

Migrating to Redshift: Rethinking and Scaling Analytics Efficiently
Shipsy's Dev team scales the client-initiated analytics and unlocks a 20000% gain in query time.

Search for a command to run...
Shipsy's Dev team scales the client-initiated analytics and unlocks a 20000% gain in query time.
Shipsy's Dev Team builds ECS-EC2 Sandbox to scale UAT testing and unlocks 70% cost savings.

The engineering team at Shipsy shares a detailed tutorial on automating front-end UI testing with Cypress in a rapid release environment.

Shipsy's Dev team creates a code-free label generator to reduce customer onboarding time and scale the label generation process.

Explore how we steered our mobile app's stability from 68% to 99%, and some hands-on developers' tips to replicate the efforts.

A walk-through of how Shipsy's Routing Playground - a DIY Smart Route Optimizer - came to be.

Analytics is the backbone of smart decision-making and is also one of the core offerings of Shipsy. However, previously we used transactional DBs for analytics that failed to cater to the growing analytics demands we had, simply because they are not built for analytics.
Not only this led to an increase in the number of support tickets, but it also slowed down our IOPS, as duplicate requests kept overburdening the servers. Hence, scaling our client-initiated or on-demand analytics has been on our minds for quite some time now.
When we say scaling, we don’t specifically refer to the number of download requests that we can successfully cater to, but also the concurrent data downloads and the time large downloads take.
There are obvious advantages of scaling data analytics, such as operational efficiency, large data handling, etc., apart from ridding the process queue choking.
Here is a glimpse of how we scaled and optimized our on-demand analytics and what benefits stemmed from our pursuit.
Incoming data download requests were processed using scripts. These scripts ran infinitely, looking for pending download requests, as shown in the following image:
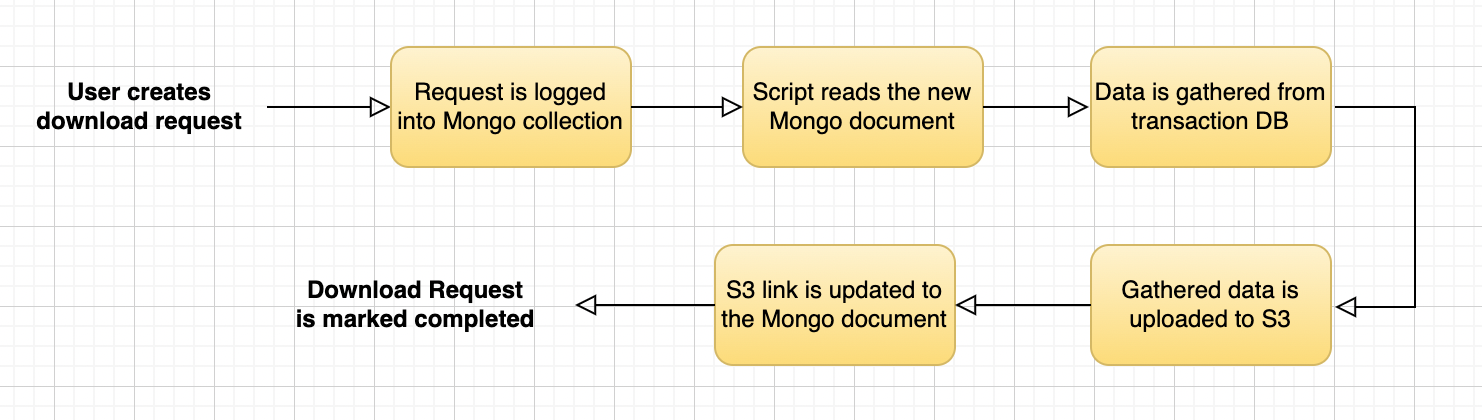
This approach was redundant because it lacked:
Things got irksome because of the following constraints stemming from the process inefficiencies:
Thus, the queue got choked with requests, most of them being duplicate ones.
This killed operational efficiency and kept the queue running for duplicate requests, leading to resource wastage.
All this called for a solution that could:
We addressed these inefficiencies by migrating to Redshift, which is specifically built for analytics
Transactional databases are not designed for performance-intensive analytics, and Redshift offered us an obvious advantage in this regard. It could execute operations on piles of data with lightning-fast speed and helped us overcome the performance and wait-time-related issues.
Further, Redshift supports regular SQL queries, so no learning curve was involved.
Next, we share glimpses of our migration to Redshift.
We created ETL pipelines to synchronize the data from our previous transactional database to Redshift:
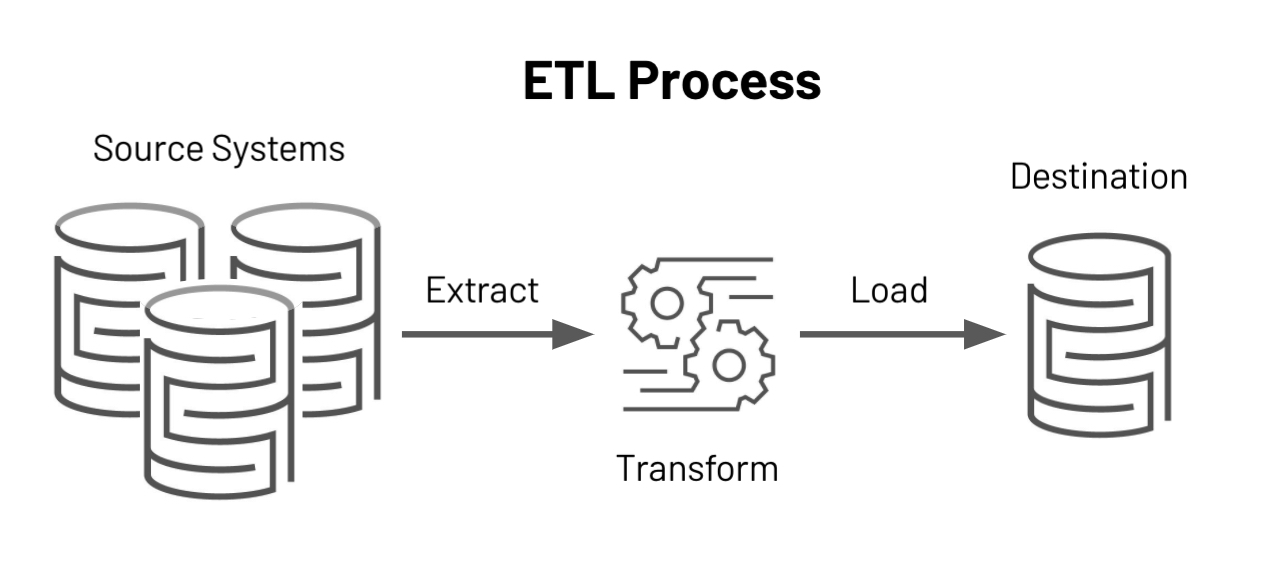
This pipeline first streams the data to S3 and then uses S3 to update the Redshift database, as shown in the following image:
Next, we used query builder to execute the data analytics queries for the Redshift schema.
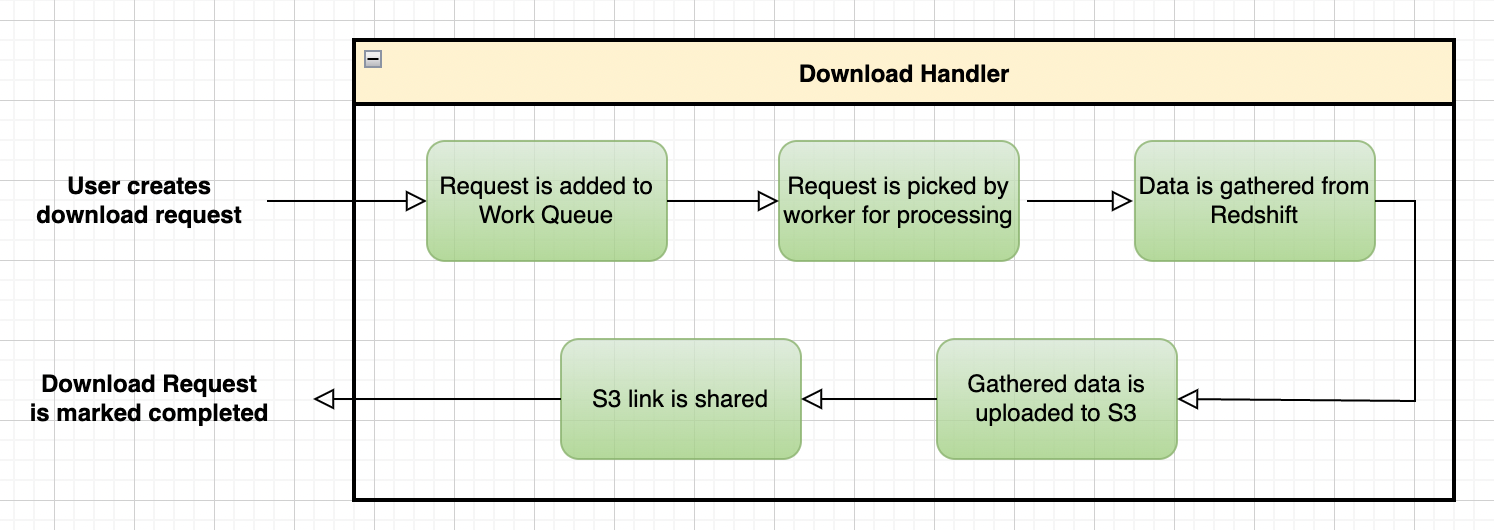
We leveraged a new service (Download Handler or DH) to achieve Concurrency and Caching.
We refined our DH operations over years of use, which helped us achieve concurrency management out of the box.
Here, we had 2 main blockers:
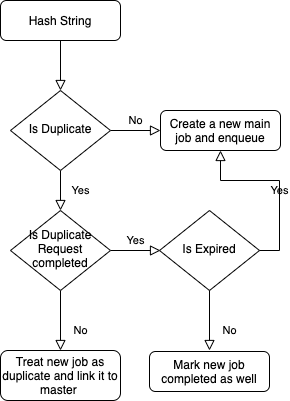
To cache any incoming download request, creating a hash key for that specific request was necessary.
For this, we used a cacheManager that did two things:
Once we have a hash string for a request, we could categorize each request into Main or Duplicate for managing cache.
All the requests with the same hash value were divided into main and duplicate.
Here is the snapshot for an overall idea:
cacheManager (params: any)
{
const { queryToExecute: query, queryParams, organisationId } = params;
const orgWiseDumpCacheConfig = config.orgWiseDumpCacheConfig || {};
let useCache = true;
if (orgWiseDumpCacheConfig[processName]) {
useCache = get(orgWiseDumpCacheConfig, `${processName}.${organisationId}.useCache`, false) || false;
}
const toRet: any = {
useCache,
};
if (useCache) {
toRet.hash = hashingFunction(query) + hashingFunction(queryParams, { unorderedArrays: true });
toRet.ttl = get(orgWiseDumpCacheConfig, `${processName}.${organisationId}.ttl`, 300000) || 300000;
}
return toRet;
}
Once a request came in, the hash value was checked for the master or slave category, and if the request was a duplicate one, it was linked to the master request.
Once the master request was completed, all the slave requests were also marked complete.
Here is the complete flowchart of the entire process:
For analytics, we treated Redshift as a normal transactional data source and created a new dbId in DH.
So, an analytics dump handler would look like a normal transactional database dump handler.
Finally, we configured our resources for a specific number of concurrent requests and were able to successfully scale our on-demand analytics.
So, if a query for Rider Level Aggregated Data for one month for a client with 2.25 M orders per month used to take 15 to 20 minutes earlier, it now got completed in a few minutes. It was a gain of 20000% in query time!
Our implementation analysis showed us the results (as shown in the following graph) that previously, roughly 50% of duplicate requests ran in the queue, draining our resources.
With the successful implementation of DH and Redshift, we scaled our operations and unlocked efficiency and speed.
Consistent innovation alongside consistent improvement - Shipsy’s development culture is a perfect combination of consistency and dynamism. We aim to keep our products, operations, and performance razor-sharp.
To be a part of our developer community, please visit our Careers Page.
Acknowledgments and Contributions
As an effort towards consistent learning and skill development, we have regular “Tech-A-Break” sessions at Shipsy where team members exchange notes on specific ideas and topics. This write-up stems from a recent Tech-A-Break session on on-demand analytics, helmed by Shikhar Sharma and Garima Goyal.